I call it my billion-dollar mistake. It was the invention of the null reference.
— Sir Tony Hoare
In mathematics, functions have a domain and a codomain. These are respectively the set of inputs and the set of possible outputs. The function then simply relates an input to an output.
For example, consider the square root function:

A function’s definition is only complete when its domain and codomain[1] are defined.
For such a common function we generally implicitly assume that the domain and codomain are the set of nonnegative real numbers:
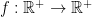
You could, however, change the function by simply extending the domain to all real numbers, which would require you to define the codomain as the set of complex numbers:
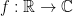
This function can then relate, say, -1 to i.
When it comes to programming, things are not much different.[2] In most languages, we still call them functions, and they still relate an input to an output (after some computation).[3]
Much like in mathematics, the input doesn’t necessarily have to be a number and can often be a composite data type, a list of arguments, or even other functions (in the case of higher-order functions, for example).
Domain and Codomain Defined via Type Signature
As far as most mainstream programming languages go, the parallels essentially stop there. In fact, most languages fail to provide us with built-in features to completely define the function by specifying its domain and codomain. And I would argue that we are missing out.
Statically typed programming languages partially offer a way to define the domain and codomain of a function, by specifying the parameters and return value types. Take the Sqrt method definition in C#:
public static double Sqrt(double x)
{
//...
}
An exception will occur if the argument passed to the function is not a double (or can’t be cast into a double). The same goes for the return value.
This type signature provides a basic element of safety. It ensures that we are actually passing a number to the function, instead of, say, null by mistake. It also ensures that we are returning a value in the first place and that the function’s return value is of the double type.
We essentially narrowed down[4] our domain and codomain to:

Amusingly, if we call Math.Sqrt(-9) in C#, the function will not raise an exception because both the argument and the return values fit the type declaration.
In fact, the function would return Double.NaN, which is the result of an undefined operation, but still technically a double. Other languages will handle the situation differently.[5]
A significant number of software bugs are caused by programmer expectations being silently violated. Wouldn’t it be nice if we could use a feature to easily specify fine-tuned conditions on the acceptable input and output values like we do in mathematics?
For instance, ensuring that an error is automatically raised at runtime if the return value of the square root function isn’t a nonnegative number?
Preconditions and Postconditions
While developing the Eiffel programming language, Prof. Bertrand Meyer came up with the idea of Design by contract (DbC). Two key concepts of this software methodology are preconditions and postconditions, which are enforced integrity checks on specified input and output values, respectively.
Preconditions are slowly becoming more common. For example, Elixir has guard expressions, which allow us to limit the set of values the function will accept:
defmodule Math do
def sqrt(x) when x >= 0 do
:math.sqrt(x)
end
end
IO.puts Math.sqrt(9) # Prints 3
IO.puts Math.sqrt(-9) # Raises a FunctionClauseError
Notice how an error is raised when we are trying to call the function with an input outside of the domain specified by the guard.
Guard expressions in named functions were introduced in Elixir in order to fully flesh out its powerful pattern matching capabilities.[6] Nevertheless, they act as preconditions that enable us to define the domain of the function.
To enforce checks on return values we need postconditions. For this example, I’ll use Clojure since it provides both preconditions and postconditions:
(defn limited-sqrt [x]
{:pre [(pos? x)]
:post [(>= % 0), (< % 10)]}
(Math/sqrt x))
(limited-sqrt 9) ;; 3.0
(limited-sqrt -9) ;; AssertionError Assert failed: (pos? x)
(limited-sqrt 144) ;; AssertionError Assert failed: (< % 10)
I intentionally made the example contrived by limiting the function codomain to values between 0 and 10, to demonstrate how postconditions are also caught at runtime (line 8).
Extended Static Checking
Some programming languages take the concept further by introducing verifying compilers that check the mathematical correctness and adherence to the formal specification.
The compiler will essentially take care of traversing all possible branches to determine whether the range of values the program could calculate meets the specification for the given function.
Creating such a compiler for an existing language is extremely hard. We are always contending with the halting problem. It is possible, however, to design languages specifically with that aim in mind.
Whiley is one such language for the JVM.
Consider this example:
import whiley.lang.System
function max(int x, int y) -> (int z)
ensures x == z || y == z
ensures x <= z && y <= z:
if x > y:
return x
else:
return y
method main(System.Console console):
console.out.println(max(4, 10))
Whiley’s compiler will verify that x, y, and z meet the conditions indicated in the specification (on lines 4 and 5). Namely, that the returned value is either of the two arguments and that both of them are less than or equal to it.
If we create a faulty version of the algorithm as shown below, we’ll catch the error before even running the program:
import whiley.lang.System
// Bad implementation
function max(int x, int y) -> (int z)
ensures x == z || y == z
ensures x <= z && y <= z:
if x > y:
return y
else:
return x
method main(System.Console console):
console.out.println(max(4, 10))
In fact, although max(4, 10) does not enter the if branch, the compiler determines that there are inputs for which that return y would not satisfy the highlighted postcondition.
True enough if you consider max(3, 2) for a moment. x (3) > y (2), so in this faulty implementation, we return z (2). However, x (3) is not less than or equal to z (2), so the postcondition fails.
Whiley is an extreme case of course, and as discussed, its verifying compiler is a virtually intractable problem for regular programming languages which were not specifically designed for it. Nevertheless, I wanted to show you how far this powerful concept can be pushed.
Conclusion
I would love to see pre and postconditions become built-in features of more mainstream programming languages.
Especially since many mainstream programming languages don’t offer referential transparency. Side effects caused by mutable data structures and having to account for state mean that we have even less predictability about return values than in purely functional programming languages.
As shown by Elixir, Clojure, and even Whiley, adding such specifications doesn’t require any significant syntactic overhead either.
With dynamically typed programming languages we stress the importance of having tests because we don’t have a compiler to catch as many of our mistakes. (Though testing is key either way.)
Pre and postconditions add a complementary layer of safety, regardless of the language’s typing system. By using both Design by Contract principles and testing, we can build more robust software. (Definitely check out other features of DbC as well, including class invariants. There are lots of good ideas in there.)
If you’d like to get started, you can probably find a library for your favorite language. If not, creating your own should be fairly easy.
However, I’d advocate for such conditions/assertions to be a core part of most languages. And that’s because of the difference in the adoption rate of opt-in vs opt-out features.
With pre and postconditions built into the language, documented in the intro tutorial that everyone reads, you’ll cultivate a community with a penchant for defensive programming, who will actually make use of the feature.
- Some readers might be more familiar with the word range or image. In our examples, range and codomain coincide, even though in general, the range is a subset of the codomain. ^
- When a function has an algorithmic bug and we get the wrong output, we are still defining a function. Just not the intended one. ^
- I’ll use the word function even when the proper nomenclature of the specific language might call for another word, such as method. ^
- Obviously, doubles are represented in memory as double precision floating-point numbers, and therefore not actual real numbers. So they are technically a subset of the rational numbers
. ^
- Both Ruby and Julia, for example, will raise a
DomainErrorin such a scenario. ^ - Here we could have a second declaration with
when x < 0to match function calls with negative arguments, perhaps leveraging that function implementation to provide a more informative error message. ^
Get more stuff like this
Subscribe to my mailing list to receive similar updates about programming.
Thank you for subscribing. Please check your email to confirm your subscription.
Something went wrong.
When I was taking CS classes in the early 90s, this was referred to as “proving the correctness of your code”…
…basically are all the pre- and post- conditions satisfiable under all conditions? Will the correct values be returned under all circunstances?
It was a little overly formal to use every day, but I’d hope would be something all programmers are taught to keep in mind. I forget the text we used, but it was one of Dijkstra’s.