For the past ten years, I’ve been working on a multitude of projects within IBM. Being part of the Emerging Technologies team, in the IBM Analytics group, I get to use (and often implement) some really cool technology.
However, technology changes quickly and so has my job over the years. I’m still a software developer and technical evangelist, but my team’s name, scope, and goals have evolved over the years to keep up with the rapidly changing technological landscape.
In recent times, my attention has been focused on two projects, The first, a tool for data scientists, will be discussed in this post, and I’ll introduce you to the second in next week’s post.
This first project is called Data Scientist Workbench. It’s an all-in-one solution for programmers, data engineers, data journalists, and data scientists who are interested in running their data analysis in the cloud. Oh, and it’s absolutely free, no catches or strings attached.
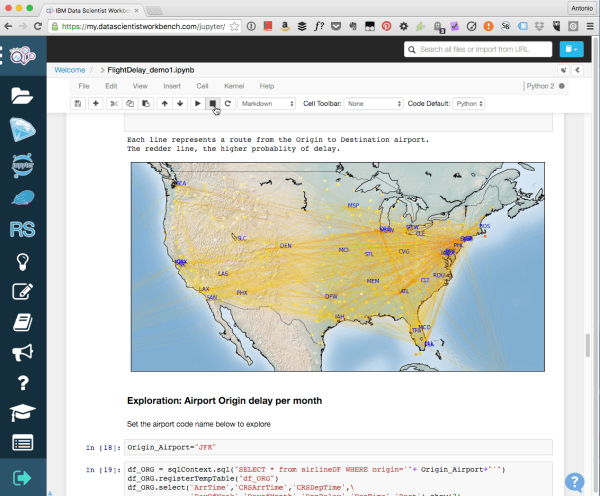
It includes Jupyter notebooks (often simply known as IPython notebooks amongst Python developers), Apache Zeppelin notebooks, a web version of RStudio IDE, OpenRefine to clean messy data before processing, and Apache Spark to handle large volumes of data.
Being a well-orchestrated collection of Open Source tools, your notebooks and data are not locked and can be exported for offline use whenever you want.
Python, R, and Scala are supported at the time of writing. Your workbench runs in a virtual machine which currently provides you with 100 GB of disk space, and 16 GB of RAM. This leads to processing that is faster than most people’s laptops. Thus you don’t have to mess your laptop up, slow it down, or spend hours installing anything. Instead, everything can be handled conveniently from a browser, from anywhere you find yourself.
Speaking of adding things, many libraries can be installed independently by you within the notebook through a command such as !pip install. If your library has OS dependencies that are not installed within your instance, you can ask our Toronto-based team for help. We are attentive and responsive to user requests and feedback, and will try to accommodate most reasonable requests in a timely manner.
On top of the usual features you might be familiar with, if you have played with, say, Jupyter notebooks, the Data Scientist Workbench adds a host of nice features such as drag and drop to upload of files, sharing of notebooks (including publishing them as Github Gists), the ability to import such links by just pasting them in the search box, and pre-created sample tutorials.
These tutorials can be imported with a single click, so that you can learn not only about DSWB (as we like to shorten it), but also familiarize yourself with the data science, big data, and machine learning technologies covered within.
So far the feedback I’ve received from people at meetups and data science hackathons I’ve been involved in has been universally positive. This is not to say that it’s perfect, of course, but it is a genuinely useful tool that is provided, again, entirely for free.
Above all, our small team launched it as a startup would. We created an MVP (Minimum Viable Product), and set it free, iteratively improving it quickly, incorporating user feedback, including both praise and complaints, as much as possible.
I think it’s a cool product that you’ll enjoy and I would like to personally invite you to try it out. Specifically:
- Register here.
- As you use the workbench, please give us feedback. Click on the question mark at the bottom of the page or click on one of the many options we provide for you to contact us (see sidebar, under Resources).
We have big plans for DSWB, so it’s important that we get as much user feedback as possible, and definitely part of the reason why I’m sharing this here with all of you. Stay tuned for next week’s post about my second focus project. Even better, subscribe via RSS feed or by email.
Get more stuff like this
Subscribe to my mailing list to receive similar updates about programming.
Thank you for subscribing. Please check your email to confirm your subscription.
Something went wrong.
Hi!
Briefly tested it and want to say that DSWB has a great future on the data analysis tools market! Useful functionality along with the outstanding simplicity makes DSWB competitive among others.
Waiting for your second project description!
Good stuff, Antonio. A newer data science platform I have just learned about is https://www.bisok.com/data-science-workbench/, which apparently makes data cleansing/prep easier. Might be a good subject for a future blog to discuss data cleansing. Thanks