Counting rows is an ubiquitous operation on the web, so much so that it’s often overused. Regardless of misuse, there is no denying that the performance of counting operations has an impact on most applications. In this post I’ll discuss my findings about the performance of DB2 9.5 and MySQL 5.1 regarding counting records.
For those of you who are not into science fiction, let me clarify that the odd title of this post is a tongue-in-cheek reference to the great novel, Do Androids Dream of Electric Sheep?.
I connected to the database, created the table, imported the data and benchmarked counting operations using ActiveRecord in a standalone script. Here is the code I used:
#!/usr/bin/env ruby
require "rubygems"
require "active_record"
require 'benchmark'
ActiveRecord::Base.establish_connection(
:adapter => :mysql,
:username => "myuser",
:password => "mypass",
:database => "mydb")
ActiveRecord::Schema.define do
create_table :people, :force => true do |t|
t.string :name, :null => false
t.string :fbid, :null => false
t.string :gender
t.string :profession
end
end
class Person < ActiveRecord::Base
end
# This can be sped up by performing an import instead
Person.transaction do
File.open("person.tsv").each_line do |line|
line = line.split(/\t/)
p = Person.new
p.name = line[0]
p.fbid = line[1]
p.gender = line[6]
p.profession = line[17]
p.save!
end
end
n = 100
Benchmark.bm(26) do |x|
x.report("Count all:") { n.times { Person.count } }
x.report("Count profession:") { n.times { Person.count(:profession) } }
x.report("Count females:") do
n.times { Person.count(:conditions => "gender = 'Female'") }
end
x.report("Count males w/ profession:") do
n.times { Person.count(:profession, :conditions => "gender = 'Male'") }
end
end
Please note that importing records in a huge transaction containing hundreds of thousands of INSERT operations is far from the most efficient way to import. Massive imports of data using the load/import facilities provided by each database is the way to go (also see the ar-extensions plugin). The lengthy import wasn’t benchmarked here though, so it isn’t determinant for this article.
people.tsv is a 92.7 MB tab separated values file that contains 875,857 records from the Freebase project (in my file I removed the header line, leaving only records).
For those who are not familiar with ActiveRecord, the queries executed behind the scenes are (in order):
SELECT count(*) AS count_all FROM people
SELECT count(people.profession) AS count_profession FROM people
SELECT count(*) AS count_all FROM people WHERE (gender = 'Female')
SELECT count(people.profession) AS count_profession FROM people WHERE (gender = 'Male')
While the table definition (for MySQL) is:
CREATE TABLE `people` (
`id` int(11) DEFAULT NULL auto_increment PRIMARY KEY,
`name` varchar(255) NOT NULL,
`fbid` varchar(255) NOT NULL,
`gender` varchar(255),
`profession` varchar(255)
) ENGINE=InnoDB
As easily verified by enabling logging with:
ActiveRecord::Base.logger = Logger.new(STDOUT)
Without much further ado, here are the times I obtained on my last generation MacBook Pro 2.66 GHz with 4 GB DDR3 RAM, and 320 GB @ 7200 rpm hard disk, running Mac OS X Leopard:
MySQL:
Count all: 42.467522
Count profession: 52.130935
Count females: 54.575469
Count males w/ profession: 64.046631
DB2:
Count all: 5.818485
Count profession: 7.714391
Count females: 8.556377
Count males w/ profession: 9.656739
Or in graph form:
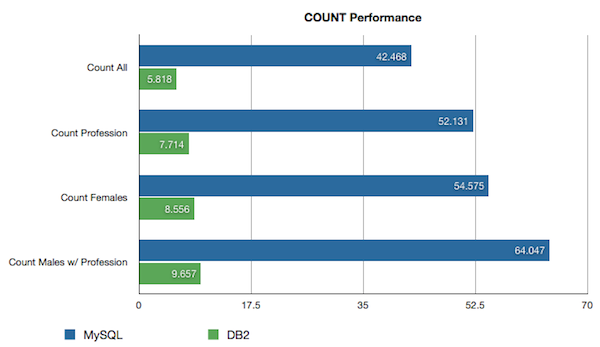
That’s an impressive difference. To be exact, in this example DB2 was between 6 and 7 times faster than MySQL. In the case of COUNT(*), DB2 counted almost a million records in 58 milliseconds, or in about the blink of an eye according to Wolfram Alpha.
For those who are skeptical, please note that DB2 was not manually fine-tuned in any way. The client codepage was set to 1252 to allow Greek letters, and the log size was increased to permit such a huge transaction during the import. That’s it, no optimizations were attempted. This is DB2 Express-C out of the box. It looks like smart androids count electric sheep with DB2 after all. 😛
The advantages of DB2 over MySQL when dealing with a massive volume of traffic are well known (and not limited to performance either), but DB2 can dramatically improve performance even for your average web application. And DB2 9.7, which will be released this month, increases the performance and the ability to self-tune itself to the available resources and required workload even further. If you’d like to try DB2 Express-C for yourself, you can download it here. It doesn’t cost you a dime to obtain and can be used for development, testing and production absolutely free of charge.
Get more stuff like this
Subscribe to my mailing list to receive similar updates about programming.
Thank you for subscribing. Please check your email to confirm your subscription.
Something went wrong.
impressive!
I would like to see postgres, could you include it in your benchmarks?
I’d like to second david’s request for a postgres take on the benchmarks.
In addition to Postgres, I would be very interested to see similar benchmarks for other MySQL table types than InnoDB. Could you add such tests and update your article?
Hi guys,
I’ll see what I can do next week. Have a great weekend! 🙂
Wow, very nice. I’m also very curious to see postgres.
Given that the gender column has only two possible values despite being a varchar, shouldn’t this have an index? It would be interesting comparing performance numbers with and without indices.
Hi
Unfortunately this is a known limitation of the innodb mysql backend.
Mysql’s innodb backend doesn’t cache “select count(*)” requests. So while db2 is able to simply return the last result from it’s cache, mysql has to actually count the number of matching records by traversing the index.
If you were to do searches with a randomly changing “where” clause, you’d find the numbers closer. That’s contrary to your article’s intent, of course, but it’ll be more accurate. I generally do “select count(*) from some_table where foreign_key_id = 123” – so doing a similar query will give us additional data.
Some of the other mysql database backends do return cached results, afaik. But activerecord defaults to innodb for transaction support.
Have a look at this – “way back” from 2006.
http://www.mysqlperformanceblog.com/2006/12/01/count-for-innodb-tables/ for more information.
And this has some explanation of why:
http://www.scribd.com/doc/2085411/MySQL-UC-2007-Innodb-Performance-Optimization
Oskar
It is widely known that COUNT(*) is not InnoDB’s strength. Try MyISAM just for kicks 🙂
Other than that, there’s so much wrong with micro benchmarks like this. It gives people the wrong ideas. I hope these kinds of comparisons are only taken into account when *all* other things are equal — and they rarely are. Or more elaborate: http://jan.prima.de/~jan/plok/archives/175-Benchmarks-You-are-Doing-it-Wrong.html
Can you repeat this for DB2 on the iSeries?
@Marcus: An index on gender significantly speeds up “Count females” for both DB2 and MySQL. However this significantly slows down “Count males /w profession” too. (In both cases, DB2 would still be several times faster.)
MyISAM cannot be called a RDBMS backend; it is nothing more than a file handler, which is why it has always been fast, it provides no Relational or Database Services. If that’s all you want, then fine.
@Robert The only point that MyISAM makes is that it uses a cached index number where InnoDB will do an index scan. yet another proof of the silliness of micro benchmarks.
This benchmark can be translated into: “how long does it take to repeat the same COUNT query 100 times.” This is a naive (at best) benchmark that doesn’t tell me nothing about the database potential. But anyway, if you enable the query cache in MySQL, the repetition of 100 queries is at least three times faster than DB2.
Try
set global query_cache_size=1024*1024;
and repeat this test.
Moreover: the table structure doesn’t correspond to the data from the freebase project. These androids don’t strike me as extremely reliable …
What about posting the database configuration settings? I fully agree with Jan, that this article is a primary example of how silly micro benchmarks are and how misleading. DB2 does NOT need this kind of posts to be recognized as a great database. It all depends on the context and the use-case and this article is ignoring context.
Now, I’m not a PostgreSQL expert, but it is my understanding that PG will create bitmap indexes /on the fly/ to satisfy such lookups on non-indexed columns.
This would make a tremendous difference in such a scenario, especially when the query cache is disabled in MySQL.
Gender is a low cardinality column, so bitmaps are extremely useful with such data.
So if PG is creating the bitmap indexes dynamically, that shows why this is faster, and is a good argument for the feature.
Would you kindly provide PG and MySQL explain plan for your queries so that we may figure out what is going on?
I took a look at the feature, and it seems that PG will dynamically combine indexes using bitmaps. I guess this is similar to the ‘index merge’ functionality provided by MySQL.
Wow. I shouldn’t read things in the middle of the night. DB2 not PG. Oops.
*slaps forehead*
Guys, I just want to clarify a few points. InnoDB was used because it’s the default – and most widely adopted – engine in the Rails community. You may notice that an id column was added for ActiveRecord, and that I only used 4 columns from the initial dataset for the sake of simplicity. To keep things simple, I used the default limits which are provided by ActiveRecord (e.g., varchar(255)). This is a simple, micro-benchmark which doesn’t need to prove much. It simply shows that with this data, under these conditions, DB2 is much faster than MySQL.
The reasons for choosing DB2 over MySQL are many, and they are not all related to performance. And even when considering performance alone, this post didn’t set out to prove that DB2 is faster than MySQL in general. There are industry benchmarks that cost millions of dollars to run that take into account all the possible moving parts. You can’t expect that from a simple post. I observed some data under particular circumstances and reported the outcome. While it is undisputed that DB2’s counting abilities are still faster than MySQL with the InnoDB engine, this post only claims that with this data, for the query used, DB2 was faster than MySQL. And I think that’s fair.
The “100 times repetition” freaked a few people out. I understand that. Please bear in mind though that I went for 100 iterations only after having seen somewhat comparable times obtained for the first execution of each query (i.e., n=1).
Yes, but you still didn’t address the point. The way your queries were performed acted precisely on the LEAST efficient operation you possibly could have chosen for MySQL. Regardless of whether it was done on purpose, it does skew the results.
Were you to add indexes, and count on indexed fields rather than (*), the performance for InnoDB in MySQL goes up dramatically. In one case, where I had a huge database (millions of records), the difference was between a full 10 minutes using count (*) and only a couple of seconds using count (indexed column).
Perhaps DB2 would outperform MySQL anyway, but, unintentional as it may be, this was still not a valid comparison. It is rather like racing a Ford sports car against a Chevy sports car, when the gas pedal on the Chevy has a block underneath that only lets the pedal go part way down.
I am surprised and amazed how many people are saying that InnoDB is lousy at COUNT(*) so, Antonio, you should use MyISAM instead. Isn’t the point of measuring things to compare them and to identify strengths and weaknesses? So, if Antonio did a benchmark that found that MyISAM did not do subselects very well then people would cry wolf and say you should have done this with InnoDB?
I think the benchmark is right on. If you are a Ruby on Rails programmer it is helpful to know how fast your object.count method will perform with MySQL vs. DB2. Majority of RoR programmers use MySQL and object.count is a common operation.
To be clear, what I am saying is: Yes, this was just a “micro-benchmark”, and one should not read too much into that. However, under the circumstances, this benchmark does in fact NOT show what it purports to show: that DB2 is GENERALLY faster than MySQL.
Lonny wrote:
Were you to add indexes, and count on indexed fields rather than (*), the performance for InnoDB in MySQL goes up dramatically.
As I mentioned before, adding an index improves the results a lot for COUNT(indexed field) but it does so in a way that is proportionate to the results shown here. This means that DB2 still is several times faster than MySQL when counting records, regardless of whether an index has been defined on a column for both databases or not.
It would be nice to do a follow up post which includes indexes and a few million records, but I suspect that people would still find other reasons to complain about the outcome. So I’m not so sure it is worth the effort.
And just to clarify something once again, this post was not meant to demonstrate that DB2 is generally faster than MySQL, even if such is the case.
My initial reaction to this result is that it was a ‘bad benchmark’ because a significant difference was reported without explanation. And my first guess was that DB2 cached the table in the DBMS buffer cache and InnoDB did not because of different configurations.
My reaction was probably wrong and Antonio may have found an interesting result and something we need to investigate for MySQL.
Is DB2 that much more efficient than MySQL/InnoDB? Note that MyISAM is slower than InnoDB when there is anything in the WHERE clause that prevents it from using the codepath for fast count(*) queries.
When I run ‘select count(*)’ on a table with a similar size and no indexes, the query takes ~0.4 seconds which is close to the result here. Maybe DB2 is that much faster on count queries and we need to fix MySQL.
From oprofile, these are the top 4 functions:
25.0744 rec_get_offsets_func
19.3973 row_search_for_mysql
11.1162 buf_page_optimistic_get_func
10.1157 mtr_commit
I find it hard to believe that any Rails app would use MyISAM tables, unless the developers don’t plan to use transactions (scary!) AND they have no intention of using WHERE clauses. In which case, maybe they can replace both MySQL and DB2 with a flat file or two.